---
datasets:
- Scicom-intl/Malaysian-Instructions
base_model:
- Qwen/Qwen3-235B-A22B-Instruct-2507
---
# Qwen3-235B-A22B-Instruct-2507-Malaysian
SFT LoRA [Qwen/Qwen3-235B-A22B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507) on [Scicom-intl/Malaysian-Instructions/commit/288b358a57765a735d588f73e5e6c212c81429bd](https://huggingface.co/datasets/Scicom-intl/Malaysian-Instructions/commit/288b358a57765a735d588f73e5e6c212c81429bd)
1. MoE LoRA SFT done using FSDP2 Fused MoE.
2. Multipacking variable length 16384 context length, with global batch size of 32, so global total tokens is 524288.
3. All linear layers with experts, rank 256 with alpha multiply by 2.0 + .
4. Liger fused cross entropy.
5. 1e-4 learning rate, 50 warmup, 3 epoch only.
+ with the rank of each equal to the total rank divided by the number of active experts, https://thinkingmachines.ai/blog/lora/
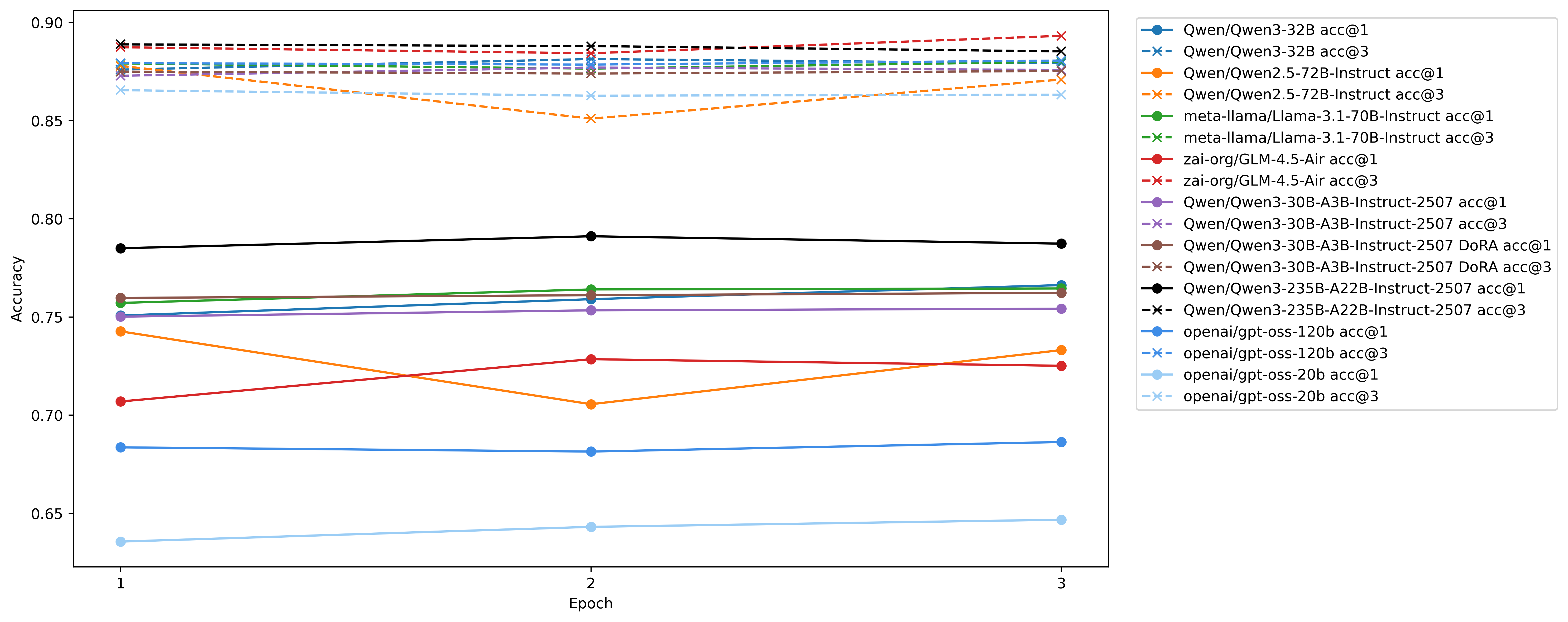
## We only upload the best model
 ## Source code
Source code at https://github.com/Scicom-AI-Enterprise-Organization/small-ablation/blob/main/malaysian-sft
## Acknowledgement
Special thanks to https://www.scitix.ai/ for H100 Node!
## Source code
Source code at https://github.com/Scicom-AI-Enterprise-Organization/small-ablation/blob/main/malaysian-sft
## Acknowledgement
Special thanks to https://www.scitix.ai/ for H100 Node!