---
license: apache-2.0
language:
- ca
- es
- en
- gl
- pt
- eu
metrics:
- bleu
- wer
- comet
base_model:
- BSC-LT/salamandraTA-7b-instruct
---
# SalamandraTAV-7b Model Card
SalamandraTAV-7b is a Speech To Text translation Speech LLM that has been finetuned from [salamandraTA-7b-instruct](https://huggingface.co/BSC-LT/salamandraTA-7b-instruct).
SalamandraTAV-7b is proficient in 6 Iberic languages plus English, and supports the following translation-related tasks: Automatic Speech Recognition, Text To Text Translation, Speech To Text Translation, Spoken Language Identification.
> [!WARNING]
> **DISCLAIMER:** This version of Salamandra is tailored exclusively for speech translation tasks. It lacks chat capabilities and has not been trained with any chat instructions.
Table of contents
- [Model Details](#model-details)
- [Intended Use](#intended-use)
- [Hardware and Software](#hardware-and-software)
- [How to use](#how-to-use)
- [Training Data](#training-data)
- [Evaluation](#evaluation)
- [Additional Information](#additional-information)
---
## Model Details
### Description
SalamandraTAV-7b is a finetuned version of [salamandraTA-7b-instruct](https://huggingface.co/BSC-LT/salamandraTA-7b-instruct) using [mhubert-base-25hz](https://huggingface.co/slprl/mhubert-base-25hz) as the speech encoder. It has been trained on 12,000 hours of Automatic Speech Recognition, 900 hours of Speech-To-Text Translation data and 113M target tokens of Text-To-Text Translation to mantain the original model's performance.
---
## Intended Use
The model is intended for both research and commercial use for the speech to text translation task in the following languages: Asturian, Basque, Catalan, English, Galician, Portuguese and Spanish.
---
## Hardware and Software
### Training Framework
The code used to train SalamandraTAV-7b is based on the [Transformers](https://huggingface.co/docs/transformers/) library, and will be publicly available soon.
### Compute Infrastructure
This model was trained on [MareNostrum 5](https://www.bsc.es/ca/marenostrum/marenostrum-5), a pre-exascale EuroHPC supercomputer hosted and
operated by [Barcelona Supercomputing Center](https://www.bsc.es/).
Training was conducted on 4 nodes, each with the following specifications:
- 4x Nvidia Hopper GPUs with 64GB HBM2 memory
- 2x Intel Sapphire Rapids 8460Y+ at 2.3Ghz and 32c each (64 cores)
- 4x NDR200 (BW per node 800Gb/s)
- 512 GB of Main memory (DDR5)
---
## How to use
> [!NOTE] **Requirements**
> To use this model, ensure you have the following Python packages installed:
> `transformers`, `torch`, `torchaudio`, `joblib`, `sentencepiece`, `protobuf`, `scikit-learn`, `langcodes`, `soundfile`
The easiest way to use the model is using the custom pipeline `multimodal_mt`:
```python
from transformers import pipeline
pipe = pipeline(
task="multimodal_mt",
model="langtech-veu/salamandra-TAV-7b",
trust_remote_code=True
)
```
Specify an audio file (can be a URL or a local file path):
```python
audio_path = "https://github.com/voxserv/audio_quality_testing_samples/raw/refs/heads/master/orig/127389__acclivity__thetimehascome.wav" # in English
```
Define the generation parameters:
```python
generation_kwargs = {
"beam_size": 5,
"max_new_tokens": 100
}
```
### Direct Speech-to-Text Translation (S2TT)
Run the S2TT pipeline, specifying the target language:
```python
translation = pipe(audio_path, mode="s2tt", tgt_lang="Spanish", **generation_kwargs)
```
Optionally, you can also specify the source language:
```python
translation = pipe(audio_path, mode="s2tt", src_lang="English", tgt_lang="Spanish", **generation_kwargs)
```
### Cascaded Speech-to-Text Translation (ASR+S2TT)
Run the S2TT pipeline, specifying the target language:
```python
transcription = pipe(audio_path, mode="asr", **generation_kwargs)
translation = pipe(transcription, mode="t2tt", tgt_lang="Spanish", **generation_kwargs)
```
Optionally, you can also specify the source language:
```python
transcription = pipe(audio_path, mode="asr", src_lang="English", **generation_kwargs)
translation = pipe(transcription, mode="t2tt", src_lang="English", tgt_lang="Spanish", **generation_kwargs)
```
### Speech-to-Text Translation with CoT (S2TT-CoT)
This is a variant which uses a CoT mechanism to generate the translation by transcribing it first.
Run the S2TT pipeline, specifying the target language:
```python
history = pipe(audio_path, return_chat_history=True, mode="asr", **generation_kwargs)
translation = pipe(history, mode="t2tt", tgt_lang="Spanish", **generation_kwargs)
```
Optionally, you can also specify the source language:
```python
history = pipe(audio_path, return_chat_history=True, mode="asr", src_lang="English", **generation_kwargs)
translation = pipe(history, mode="t2tt", src_lang="English", tgt_lang="Spanish", **generation_kwargs)
```
#### Advanced Usage
If you are interested in getting the intermediate results, you can do it as follows:
```python
history = pipe(audio_path, return_chat_history=True, mode="asr", **generation_kwargs)
transcription = history.get_assistant_messages()[-1]
history = pipe(history, return_chat_history=True, mode="t2tt", tgt_lang="Spanish", **generation_kwargs)
translation = history.get_assistant_messages()[-1]
history = pipe(history, return_chat_history=True, mode="lid", **generation_kwargs)
src_language = history.get_assistant_messages()[-1]
```
## Training Data
### Global Summary
| Data Type | Hours | Samples | Tokens (target) | Tokens (total) |
|:--------------|:----------|:-----------|:------------------|:---------------|
| **ASR** | 12,147.5h | 5,207,686 | 582,567,674 | 4,180,709,878 |
| **S2TT** | 896h | 556,664 | 28,297,402 | 153,376,912 |
| **T2TT** | - | 2,242,354 | 112,837,123 | 220,328,525 |
### Automatic Speech Recognition
> [!NOTE] To ensure reliable evaluation, we excluded from the Common Voice 21.0 train set all samples that overlap with the CoVoST 2 dev and test sets.
| Dataset | ast | ca | en | es | eu | gl | oc | pt | Total |
|:----------------------------------------------------------------------------------------------------|:-------|:------|:------|:------|:------|:------|:------|:------|:------|
| [Common Voice Corpus 21.0](https://commonvoice.mozilla.org/en/datasets) (train) | 0.5h | 1775h | 1762h | 494h | 166.5h| 90.5h | 0.5h | 23h | 4312h |
| [VoxPopuli](https://github.com/facebookresearch/voxpopuli) (train) | | | 501h | 149h | | | | | 650h |
| [ParlamentParla)](https://zenodo.org/records/5541827) (train_clean) | | 200h | | | | | | | 200h |
| [Multilingual LibriSpeech](https://www.openslr.org/94/) (train) | | |4466.5h| 917h | | | | 161h | 5545h |
| [basque_parliment_1](https://huggingface.co/datasets/gttsehu/basque_parliament_1) (train_clean) | | | |937.5h | 363.5h| | | | 1301h |
| [CRPIH_UVigo-GL-Voices](https://zenodo.org/records/8027725) | | | | | | 21h | | | 21h |
| [festcat_trimmed_denoised](https://huggingface.co/datasets/projecte-aina/festcat_trimmed_denoised) | |22.5h | | | | | | | 22.5h |
| [LaFrescat](https://huggingface.co/datasets/projecte-aina/LaFrescat) | | 3.5h | | | | | | | 3.5h |
| [Google Crowdsource](https://github.com/google/language-resources) | | 9.5h | | | 14h | 10.5h | | | 33.5h |
| [Nos_Celtia-GL](https://zenodo.org/records/7716958) | | | | | | 24h | | | 24h |
| [Nos_Transcrispeech-GL](https://huggingface.co/datasets/proxectonos/Nos_Transcrispeech-GL) (train) | | | | | | 35h | | | 35h |
| Total (hours) | 0.5h |2010.5h|6729.5h|2497.5h| 544h | 181h | 0.5h | 184h |12147.5h|
### Speech-To-Text Translation
> [!NOTE] To ensure reliable evaluation, we excluded from the CoVoST 2 train set all samples that overlap with the Common Voice 21.0 dev and test sets.
| Dataset | ca-en | en-ca | en-es | en-pt | es-en | es-pt | pt-en | pt-es | Total |
|:----------------------------------------------------------------------------------------------------|:------|:------|:------|:------|:------|:------|:------|:------|:------|
| [CoVoST 2](https://github.com/facebookresearch/covost/) (train) | 135.5h| 430h | | | 113h | | 10.5h | | 689h |
| [Europarl-ST v1.1](https://www.mllp.upv.es/europarl-st/) (train) | | | 75.5h | 74h | 20.5h | 12.5h | 14.5h | 9.5h | 207h |
| Total (hours) | 135.5h| 430h | 75.5h | 74h | 133.5h| 12.5h | 25h | 9.5h | 896h |
### Text-To-Text Translation
For T2TT data, we filtered [Wikimedia](https://dumps.wikimedia.org/other/contenttranslation/20250801/) and [Tatoeba](https://downloads.tatoeba.org/exports/per_language/) datasets using the following criteria:
1. Sample obtained a [GlotLID v3](https://github.com/cisnlp/GlotLID) target language probability of at least 50%
2. Sample contains between 5 and 100 words
3. Sample obtained a [BLASER 2.0](https://huggingface.co/facebook/blaser-2.0-qe) score higher than 3.75
Obtaining 102,845,818 target tokens for Wikimedia and 9,991,305 target tokens for Tatoeba, with the following language distribution:
| Language | As Source (samples) | (%) | As Target (samples) | (%) |
|:---------|--------------------:|:--------------|--------------------:|:--------------|
| **ast** | 848 | 0.0% | 11,800 | 0.5% |
| **ca** | 44,278 | 2.0% | 272,250 | 12.1% |
| **en** | 1,353,784 | 60.4% | 412,166 | 18.4% |
| **es** | 533,330 | 23.8% | 862,276 | 38.5% |
| **eu** | 5,266 | 0.2% | 79,534 | 3.5% |
| **gl** | 14,052 | 0.6% | 85,510 | 3.8% |
| **pt** | 290,754 | 13.0% | 518,776 | 23.1% |
| **Total**| 2,242,354 | 100.0% | 2,242,354 | 100.0% |
## Evaluation
Below are the SalamandraTAV-7b evaluation results on the [Fleurs](https://huggingface.co/datasets/google/fleurs), [mintzai-ST](https://github.com/Vicomtech/mintzai-ST), [CoVoST 2](https://github.com/facebookresearch/covost/) and [Common Voice](https://commonvoice.mozilla.org/en/datasets) test sets,
compared against the state-of-the-art models: [SeamlessM4T](https://huggingface.co/facebook/seamless-m4t-v2-large), [Whisper](https://huggingface.co/openai/whisper-large-v3) and [SpireFull](https://huggingface.co/utter-project/SpireFull).
We report the following metrics:
Click to show metrics details
- `BLEU`: [sacrebleu](https://github.com/mjpost/sacrebleu) implementation. Signature: nrefs:1 | case:mixed | eff:no | tok:13a | smooth:exp | version:2.5.1.
- `XComet-XL`: [COMET](https://github.com/Unbabel/COMET) model checkpoint: [Unbabel/XCOMET-XL](https://huggingface.co/Unbabel/XCOMET-XL).
- `WER`: [jiwer](https://github.com/jitsi/jiwer) implementation. Applied the following normalization:
```python
def normalize_text_list(text_list: List[str]) -> List[str]:
normalized_list = []
for t in text_list:
# Apostrophes and quotation marks
t = t.replace("’", "'").replace("‘", "'").replace("`", "'")
t = t.replace("“", '"').replace("”", '"')
# Hyphens
t = t.replace("–", "-").replace("—", "-")
# Ellipses
t = t.replace("…", "...")
# Non-breaking spaces
t = t.replace("\u00A0", " ")
normalized_list.append(t)
return normalized_list
transformation = jiwer.Compose([
normalize_text_list,
jiwer.ToLowerCase(),
jiwer.ExpandCommonEnglishContractions(),
jiwer.RemovePunctuation(),
jiwer.RemoveWhiteSpace(replace_by_space=True),
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.ReduceToSingleSentence(),
jiwer.ReduceToListOfListOfWords()
])
```
### Speech-To-Text Translation
Results reported in bold indicate better performance than SeamlessM4T. The heatmap matrices indicate the difference in scores of each language direction.
Fleurs Test
### Fleurs Test
**BLEU**
| SalamandraTAV | ast | ca | en | es | gl | pt | Avg (tgt) |
|:--------------|-----------:|----------:|----------:|----------:|-----------:|-------------:|----------:|
| **ast** | - | **26.4** | **27.7** | **17.1** | **19.7** | **21.6** | **22.5** |
| **ca** | **22.9** | - | 39.7 | **22.2** | **29.8** | **31.0** | **29.1** |
| **en** | **24.3** | **39.1** | - | **25.5** | **32.3** | **43.0** | **32.8** |
| **es** | **13.7** | **20.8** | 24.8 | - | **18.8** | **19.1** | **19.4** |
| **gl** | **18.1** | **29.4** | 32.4 | **20.6** | - | **26.0** | **25.3** |
| **pt** | **19.9** | **30.6** | 37.0 | **20.6** | **25.6** | - | **26.7** |
| **Avg (src)** | **19.8** | **29.3** | 32.3 | **21.2** | **25.2** | **28.1** | **26.0** |
**SalamandraTAV vs SeamlessM4T BLEU Difference**
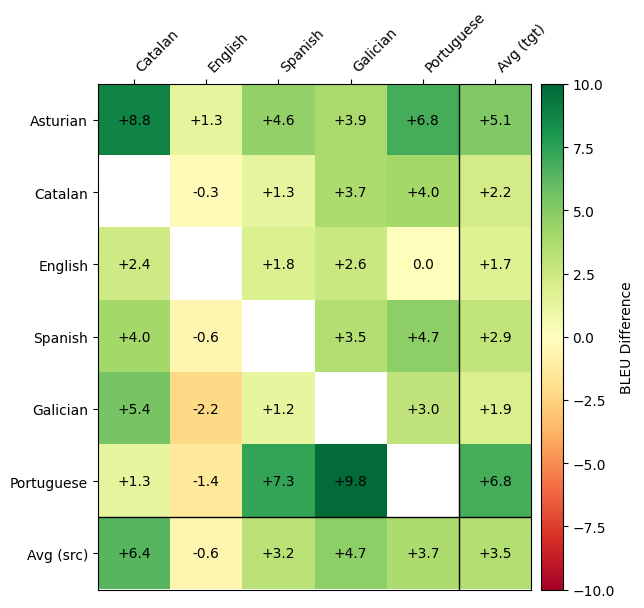
The evaluation results reported here were obtained by manually running inference with the model on the test set. We verified that the results from SeamlessM4T are consistent with the [official results](https://huggingface.co/facebook/seamless-m4t-v2-large) reported by the authors.
**XCOMET-XL**
| SalamandraTAV | ca | en | es | gl | pt | Avg (tgt) |
|:---------------|-----------:|-----------:|------------:|------------:|------------:|-----------:|
| **ca** | - | 0.9289 | **0.9114** | **0.9202** | **0.9136** | **0.9185** |
| **en** | **0.8987** | - | **0.9045** | **0.8981** | **0.9077** | **0.9023** |
| **es** | **0.9013** | **0.9257** | - | **0.9162** | **0.9110** | **0.9136** |
| **gl** | **0.8930** | 0.9024 | **0.8890** | - | **0.9005** | **0.8962** |
| **pt** | **0.8697** | 0.8912 | **0.8775** | **0.8862** | - | **0.8812** |
| **Avg (src)** | **0.8907** | 0.9121 | **0.8956** | **0.9052** | **0.9082** | **0.9023** |
**SalamandraTAV vs SeamlessM4T XCOMET-XL Difference**
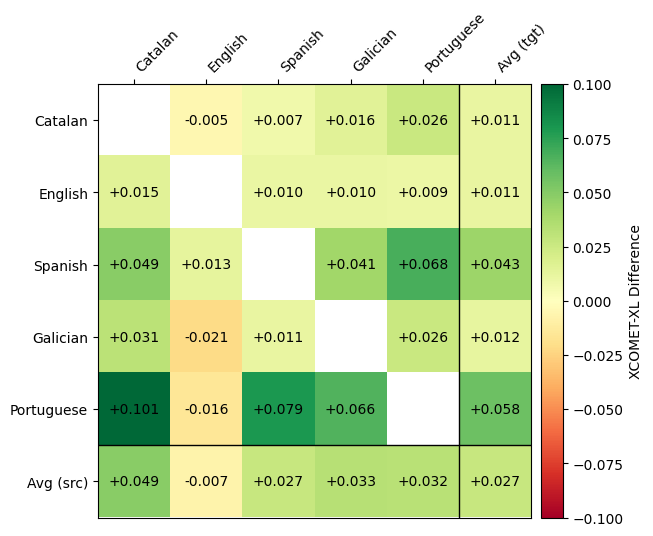
XCOMET-XL results for Asturian are not reported because it is not supported by this metric.
CoVoST 2 Test
### CoVoST 2 Test
**BLEU**
| SalamandraTAV | ca | en |
|:--------------|----------:|----------:|
| **ca** | - | **37.3** |
| **en** | 41.1 | - |
| **es** | - | **43.9** |
| **pt** | - | 49.0 |
| **Avg (src)** | 41.1 | 43.4 |
**SalamandraTAV vs SeamlessM4T BLEU Difference**
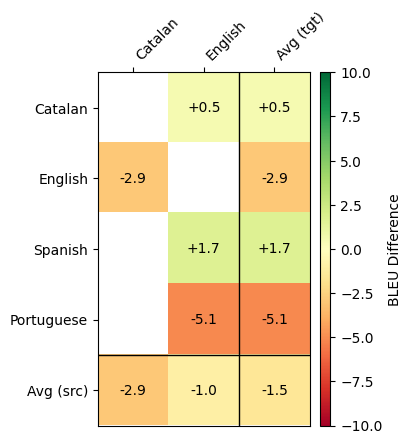
**XCOMET-XL**
| SalamandraTAV | ca | en |
|:--------------|----------:|----------:|
| **ca** | - | 0.8835 |
| **en** | 0.8454 | - |
| **es** | - | 0.9241 |
| **pt** | - | 0.8967 |
| **Avg (src)** | 0.8454 | 0.9014 |
**SalamandraTAV vs SeamlessM4T XCOMET-XL Difference**

Mintzai-ST Test
### Mintzai-ST Test
Mintzai-ST has overlap with basque_parliament_1, with which we have trained our model.
**BLEU**
| SalamandraTAV | es | eu |
|:--------------|----------:|----------:|
| **es** | - | **21.7** |
| **eu** | **26.8** | - |
**SalamandraTAV vs SeamlessM4T BLEU Difference**
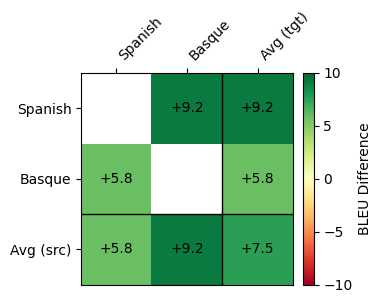
**XCOMET-XL**
| SalamandraTAV | es | eu |
|:--------------|----------:|----------:|
| **es** | - | **0.8000**|
| **eu** | **0.8329**| - |
**SalamandraTAV vs SeamlessM4T XCOMET-XL Difference**
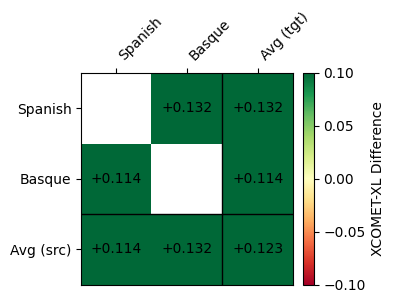
### Automatic Speech Recognition
Common Voice 21.0 Test
### Common Voice 21.0 Test
**WER**
| | SalamandraTAV | SeamlessM4T | Whisper v3 | Spire |
|:--------------|--------------:|------------:|------------:|------:|
| **ast** | **29.35** | - | - | - |
| **ca** | **7.34** | 7.89 | 14.11 | - |
| **en** | 16.65 | **9.15** | 11.13 | 22.56 |
| **es** | 7.72 | 5.64 | **5.21** | - |
| **gl** | 7.83 | **7.38** | 14.50 | - |
| **pt** | 21.80 | 19.62 | **6.85** | - |
Fleurs Test
### Fleurs Test
**WER**
| | SalamandraTAV | SeamlessM4T | Whisper v3 | Spire |
|:--------------|--------------:|------------:|------------:|------:|
| **ast** | **25.68** | - | - | - |
| **ca** | 7.34 | 5.74 | **4.88** | - |
| **en** | 8.35 | 7.66 | **4.81** | 9.07 |
| **es** | 6.04 | 5.30 | **2.95** | - |
| **gl** | 11.83 | **8.00** | 13.61 | - |
| **pt** | 10.55 | 7.94 | **3.97** | - |
Mintzai-ST Test
### Fleurs Test
**WER**
| | SalamandraTAV | SeamlessM4T | Whisper v3 |
|:--------------|--------------:|------------:|------------:|
| **es** | 8.21 | 9.24 | **7.37** |
| **eu** | **19.34** | 25.69 | 48.64 |
## Additional information
### Authors
All the members of the SalamandraTAV Team are members of the [Language Technologies Lab](https://www.bsc.es/discover-bsc/organisation/research-departments/language-technologies-unit) at the [Barcelona Supercomputing Center (BSC)](https://www.bsc.es/).
- **Core Contributors** (equal contribution, alphabetical order)
- [Gerard I. Gállego](https://www.bsc.es/gallego-olsina-gerard-ion)
- [Oriol Pareras](https://www.bsc.es/pareras-velasco-oriol)
- **Team Coordination**
- [Federico Costa](https://www.bsc.es/costa-federico)
- **Lead** (equal contribution, alphabetical order)
- [Cristina España-Bonet](https://www.bsc.es/espana-i-bonet-cristina)
- [Javier Hernando](https://www.bsc.es/hernando-pericas-francisco-javier)
### Contact
For further information, please send an email to .
### Copyright
Copyright(c) 2025 by Language Technologies Lab, Barcelona Supercomputing Center.
### Funding
This work is funded by the Ministerio para la Transformación Digital y de la Función Pública - Funded by EU – NextGenerationEU within the framework of the project Modelos del Lenguaje.
### Acknowledgements
The author thankfully acknowledges the computer resources at MareNostrum and the technical support provided by Barcelona Supercomputing Center (RES-IM-2025-2-0027).
### Disclaimer
Be aware that the model may contain biases or other unintended distortions.
When third parties deploy systems or provide services based on this model, or use the model themselves,
they bear the responsibility for mitigating any associated risks and ensuring compliance with applicable regulations,
including those governing the use of Artificial Intelligence.
The Barcelona Supercomputing Center, as the owner and creator of the model, shall not be held liable for any outcomes resulting from third-party use.
### License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Citation
If you find our model useful, we would appreciate if you could cite our work as follows:
```
@misc{bsclt2025salamandraTAV7b ,
title={salamandra-TAV-7b: a Speech-To-Text Translation model based on an end-to-end Speech LLM for Iberian Languages.},
author={SalamandraTAV Team},
organization={Barcelona Supercomputing Center},
url={https://huggingface.co/langtech-veu/salamandra-TAV-7b},
year={2025}
}
```